I occasionally hear about TCP congestion window sizes from developers and network folks. I hear gab about sliding window algorithms and ACK-based window growth (slow start), and how high RTT means bulk downloads are fated to subpar performance. And, sure, when you hit the install button on your phone, hoping you get a quick download, only to be met with a glacial download instead, it sure feels like something is wrong with your TCP parameters and it's time to crack TCP open and get tuning. But this temptation is misguided and I'd probably be frightened to hear the tweaks the average engineer would make.
No, I've been surprised to learn that most engineers have little true knowledge about how TCP actually works. Most engineers know something about the sliding window and ack-pacing, and the rest is misconception and confusion. So get ready, I aim to reduce the confusion, and discuss what really affects the rate of your bulk TCP downloads, namely CUBIC. And to add some hope for a bright future for TCP, I'll talk about BBR, a CUBIC alternative from the latency-based-congestion-detection side of the fence, as well as QUIC, a new transport protocol for the web.

Sample CUBIC TCP stream. At the orange dots, CUBIC reaches max probing and is able to grow cwnd. The gray dots show where Linux CUBIC convergence modification sets the cubic inflection point at 0.9*W_max (a cubic shape appears despite falling capacity).
First the question of tuning. It's unlikely you need to go anywhere near your system's TCP parameters. I can think of only 2 common scenarios that might warrant tuning 1. you're in a data center and want to adopt Data Center TCP for low latency environments. 2. You're using 10Gig+ links and don't trust your OS auto-tuning for high-capacity links. Aside from those two, you should trust that the tuning your system came with is solid. It's solid because engineers have been tweaking TCP over the entire history of the ARPA/inter-net, and everyone agrees TCP behavior is really important to get right.
In 1986 when the internet was still run by the government and TCP was young, engineers were learning about bad TCP behavior and networks." TCP, at the time with no congestion control (:-!) would occasionally "collapse" whole segments of the internet. Clients were programmed to respect the capacity of the machine at the other end of the connection (flow control) but not the capacity of the network. Like a basketball team mad at the ref, clients would repeatedly retransmit to the local overloaded router, not holding back despite the fact that only a trifle of packets were getting through. In 1986 in an especially bad incident, backbone links across the NSFNET, under incredible congestion, passed only 40bps, 1/1000th of their rated 32kbps capacity. The internet was suffering congestion collapse. The solution to congestion collapse was to inject into TCP congestion control and Jacobson and Karel's slow start algorithm 1.
Previously, TCP had one "window." Each client kept track of the number of bytes (receive window) its peer was prepared to read off the wire. If the client wasn't prepared to receive data, the transmitter didn't send (transmissions would just be discarded, and have to be retransmitted). As the 1986 collapses proved, the receive window wasn't enough. Like today, TCP connections weren't limited by the memory or processing of the system; the bottleneck was the network capacity. The receive windows sat wide open while the network entered congestive collapse! Jacobson and friends introduced another window, the congestion window dictating how many bytes at present could be safely transmitted without risking congestion (and collapse). A transmitting machine would look at both the receive window and the congestion window and transmit only as many packets as the more restrictive of the two allowed.
When a new TCP stream is born, it has no idea how large a link it has. It might have 1kbps throughput, or 10Gbps. Congestion control needs to find the link capacity so as to not collapse the link, and also find this capacity quickly (you don't want to spend all your time "getting up to speed"). Jacobson and friends chose a system that grows exponentially, with each ACK received triggering the release of 2 more packets. To confuse everyone, Jacobson named this exponential growth slow start. Thanks Jacobson 2.
Here in defense of the "tweakers," there is truth that tuning initial_cwnd (initial congestion window) has impact on how quickly slow start gets up to speed. Jump starting at 2^(4+n) instead of 2^(1+n) gets you to a large cwnd faster. Still, it doesn't warrant tuning. Yes, slow start is RTT-paced and slightly punishes users with high RTT. However, at the current (Linux) default of initial_cwnd of 10 packets, TCP will grow to 122Mbps of traffic within 14 cycles. With a 100ms link that's 1.4 seconds, not long in the scheme of a bulk download 3. (As for high capacity links like 10 GigE, most OSes will automatically adjust TCP parameters automatically).
The other reason tuning won't help bulk downloads: it's the server's TCP instance controlling initial_cwnd and congestion control for the downlink. Whether S3, CDN, or the App Store, in most cases you're just not in a position to tune the server. (Also, don't forget, CDNs are in the business of rapid transfers. If you think Akamai doesn't have performance engineers tuning their TCP implementations, you'd be sorely mistaken).
A related misconception I hear (that encourages initial_cwnd tweaking) is that slow start and its ACK-triggered 2^x growth, is the main driver of TCP transmit rate. Not at all. Slow start is just the starting act, less even. The vast majority of the time TCP will be in congestion avoidance with an algorithm like CUBIC at the reins. If you want to curse a name for inconsistent bulk downloads, don't curse slow start or ACK-pacing, curse CUBIC! (And then compliment it too, because it's really really neat).

Those misconceptions aside, let's return to TCP. Like the reptile brain said to underlie the mammal brain, our TCP stream (figure above) begins with ACK-paced exponential growth (slow start) until it overwhelms the link and causes loss (first peak in the figure). Then Jacobson and friends' mammal brain, congestion control, takes over and manages the stream (for the entire rest of the connection!). Congestion control's directives: operate the stream at or near link capacity, respond to changes in capacity, prevent collapse, play nice with other streams.
In 1988, our congestion control mammal brain would have been Jacobson's new algorithm, Tahoe. Tahoe was a real advance, however, instead of Tahoe, I'm going to describe CUBIC, a modern congestion control algorithm that is used by default by the Linux kernel.
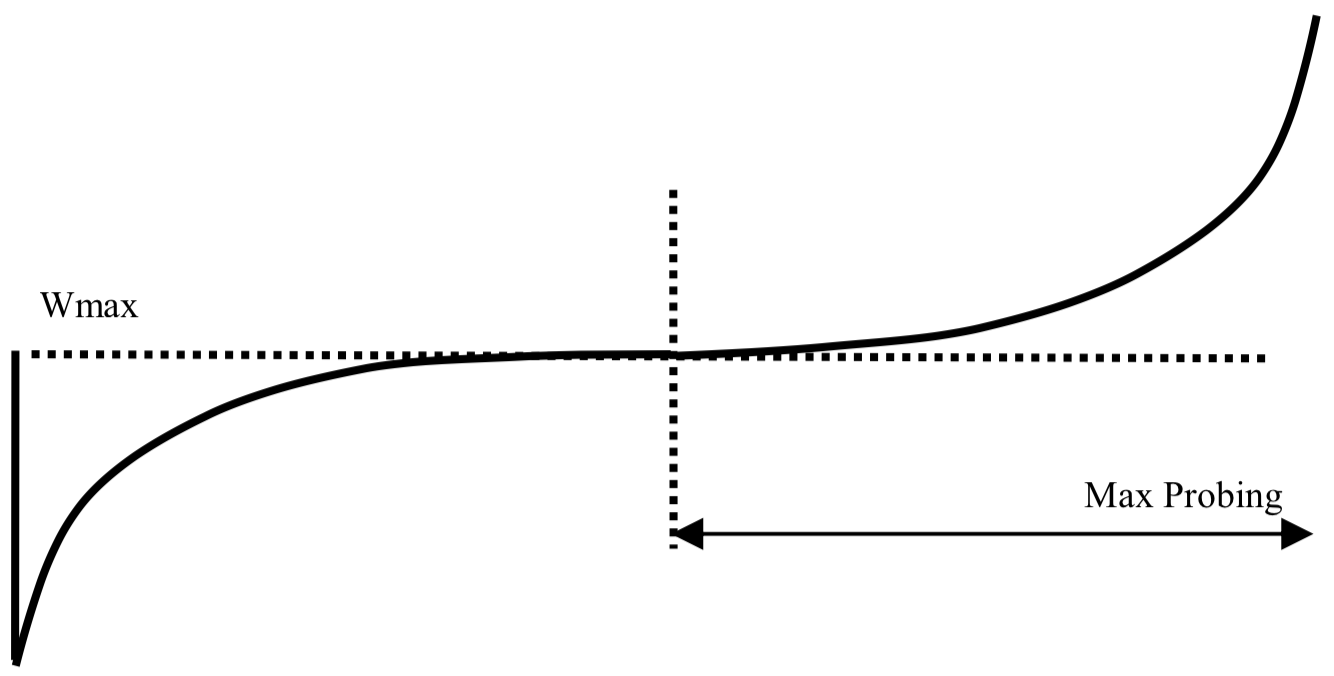
When TCP-mammal-brain CUBIC takes over, it knows W_max, the value of cwnd when TCP overwhelmed the link. CUBIC can assume the true link capacity is somewhere around W_max. In the bigger picture, CUBIC would like to exploit known link capacity, and then occasionally push past this "safe" throughput in case link capacity has increased. The "formula" is the cubic function shown below. CUBIC scales back to 0.8*W_max on loss, then draws this cubic with the inflection point (flat part) at W_max. Looking at the figure above, the first three peaks are cubic functions that were interrupted near the inflection point. They look like shark fins. Finally, you can see on the fourth cycle, capacity has increased and the stream grows through the inflection point (W_max) into the "max probing" region of the cubic. A clear cubic form appears. After a few more cycles of shark fins, this growth repeats.
The cubic shape is an optimization: time below max_throughput (some point around W_max) is waste. CUBIC grows quickly to "hug" W_max. As it approaches, growth tapers off. In comparison, earlier congestion control algorithm Reno has a sawtooth waveform and does not hug max_throughput as closely as CUBIC.
Now, something strange occurs at the right of the cwnd graph above. I've drawn a red dashed line where CUBIC has placed the inflection point (flat part of the cubic) below W_max. There is more to CUBIC than Ha et al.'s original paper. To address convergence issues (the time for multiple streams to reach equitable division of network resources). Linux places the inflection point at 0.9*W_max if throughput appears to be decreasing (W_max_prev > W_max). At steady state, this gives Linux CUBIC a cycle (alternates between W_max and 0.9*W_max).
Below you can see the Linux CUBIC versus Ha's original CUBIC. Ha's waveform is pure shark fin. We would expect this; link capacity only falls, so the cubic function never has a chance to pass the inflection point and enter the probing phase. Linux CUBIC's modification places the inflection point at 0.9*W_max every other cycle, so a cubic form appears, even though link capacity doesn't increase. You can imagine how this can cause a large flow to sit artificially low for a brief period, allowing a smaller stream to pick up bandwidth. You can also see that on the 0.9*W_max cycles, the stream approaches W_max from the max probing region and thus may more aggressively pickup available bandwidth than if it were growing through the linear center region of the cubic function.
TCP CUBIC contains another improvement from the original 2008 CUBIC paper 4. TCP now commonly uses HyStart (Hybrid Slow Start). Slow start often severely overshoots the link capacity, causing needless congestion. HyStart tracks packet timings, looking for the first hint of congestion, and sets a level, sshthresh, at which slow start is at risk of severely overwhelming the link. When sshthresh is exceeded, the stream switches to congestion control (for us, CUBIC).

An important note about RTT. CUBIC's traffic control is independent of RTT. I hear engineers complain about RTT for TCP transfer woes, but CUBIC in fact is paced by time, not ACKs/RTT. Adjusting cwnd based on time alone gives CUBIC better performance across a range of RTTs 5.
Okay, cool, slow start isn't to blame for my transfer woes, nor is flow control, or ACK-pacing. But despite TCP having gradual improvements like CUBIC, TCP isn't always consistent for bulk transfers. Give me some hope, how is the situation being improved?
Well, a promising new protocol has appeared on the horizon: Google's QUIC. But before you believe that QUIC is the brilliant new protocol that will change everything, I'm sorry to say QUIC is not a universal fix and it probably won't help bulk transfers.
In their perpetual endeavour to prove they can re-engineer and improve everything, Googlers have created a new reliable transport++ protocol, QUIC. QUIC is a TCP+TLS+HTTP/SPDY alternative with many improvements: more rapid handshakes (especially for TLS), stream multiplexing without head-of-line blocking, persistence across IP address migration, header compression, etc. QUIC's effect is to speed up web browsing by fixing various performance issues in TCP+TLS+HTTP/SPDY. Some say QUIC is the successor to TCP, but it's not true. QUIC is the evolution of TCP+TLS+SPDY that rolls those three protocols into one and makes them smarter.
For bulk transfers, what advantages does QUIC have over TCP?
Retransmitted packets are given new sequence numbers, allowing
QUICto differentiate retransmissions and delayed packets.
QUICtracks RTT and declares packets lost based on RTT time thresholds where TCP waits for retransmit requests.
QUICis expected to usepacket pacing(avoid overloading buffers by spacing out packet bursts).Though not necessarily helpful for performance,
QUICcan persist connections when IP addresses change.
Some would list Forward Error Correction (FEC) as a benefit of QUIC. Sadly the open source QUIC implementation does not use FEC and it appears the first versions of QUIC are unlikely to have FEC. So FEC is is not a benefit at present, but may be in the future. In addition, I also leave off QUIC's head-of-line blocking improvements as they are only relevant to connections with multiple streams.
And how does QUIC pan out for bulk transfers? Mixed. In some informal tests with 160ms RTT, TCP outperforms QUIC performance across packet loss values and across RTTs. However, Carlucci et al. found that QUIC outperformed TCP when packet loss increased. However, Carlucci doesn't mention their testbed RTT. If the RTT was 1ms or something very small, I would consider their results non-representative of the real world and invalid (QUIC tends to performs better at low RTT). So with current tests, it's unclear. But as I warned before, it doesn't seem that QUIC is an overwhelming improvement over TCP for bulk transfers.
Interestingly, that component that is fundamental to the performance of present-TCP - the CUBIC congestion control algorithm - is part of QUIC. CUBIC is currently the default congestion control algorithm for QUIC. Cool, but in my mind, raises questions about whether QUIC can utilize packet pacing and CUBIC at the same time.
With CUBIC at the helm of QUIC, for bulk transfers, QUIC is much more of a TCP re-implementation than a TCP revolution. (In fairness, for the web / web applications, QUIC is more of a revolution).
Fortunately, there is another technology that may tromp both QUIC and TCP CUBIC: BBR.
CUBIC and congestion control mentioned so far use packet loss as an indicator of congestion. But there is another method that may be superior. That is to monitor latency changes of the link.
Look at the figure below. In packet networks, when throughput is below capacity, router buffers are used only lightly and latency is low. But when throughput approaches capacity, those buffer fill. The buffer smooths out traffic bursts, but also increases latency as packets are forced to queue. Finally, when throughput exceeds capacity, buffers are fully utilized and the bottleneck router is forced to drop packets.
Really, you'd prefer not to depend on loss as a congestion indicator. Filling buffers and causing loss are inefficient actions that decrease the goodput (useful data transfer) of a link. CUBIC and other algorithms spend time probing into the right part of the figure below, meaning they're causing loss, retransmission, and waste. It would be far better to spend your time in the middle of the graph and avoid probing the right altogether. That's the rational behind latency-based congestion control and BBR 6.

So BBR monitors RTT and attempts to detect when packets are getting getting buffered based on timing. The larger the increase in RTT, the longer packets are being buffered, and the higher the likelihood the network is entering congestion. In theory, this allows BBR to make superior use of queues, and to avoid buffer bloat issues entirely (if you detect packet queueing, and scale back to until queueing disappears, you don't get trapped in deep buffer-bloat buffers).
This approach is not without issues. Another latency-based algorithm Vegas doesn't claim its fair share of network capacity when competing with other algorithms. When a loss-based algorithm like CUBIC probes for increased capacity, Vegas detects network queuing and backs off before before CUBIC does, leaving CUBIC to steal some of its throughput. BBR appears to have the opposite issue of Vegas. APNIC found that BBR choked out CUBIC on a 15.2ms link and grabbed slightly more than its fair share on a 298ms RTT internet test.
In fact, BBR seems to have issue co-existing with other BBR streams that have different RTT. Shiyao et al. found that on a 100Mbps link, a 50ms RTT BBR stream would steal 87.3Mbps of throughput from an existing 10ms RTT BBR stream. This imbalance continued across a range of network capacities from 10Mbps to 1Gbps with the 50ms stream receiving an average of 88.4% of the capacity.
Issues aside, Google finds BBR very performant. Google uses BBR across their backbone and see a 2-20x throughput gain. Google also claims that BBR achieves throughput at 1/2 to 1/5th the RTT of CUBIC. In the case of buffer-bloat, they claim even larger decreases in RTT.
BBR clearly has advantages. Simultaneously, BBR appears to have some co-existence issues. Google claims BBR co-existence is not so bad, and perhaps circumstances of the internet give BBR better co-existence when used at YouTube than when trialed on testbeds. Still, it seems BBR needs more testing and improvement before it is ready for widespread adoption.
So there you have it. When your app store download crawls, and you need a name to write on your voodoo doll, that name isn't ack-pacing, it isn't sliding window, it isn't flow control, and it isn't slow start. That name is CUBIC. In fairness CUBIC does a good job. CUBIC is probably the best, most robust congestion control algorithm available. But, as internet bandwidths grow and wireless represents a larger share of network links, TCP doesn't perform as desired. TCP has evolved significantly since Internet congestion collapses of the 1980s, and it continues to evolve. BBR may succeed in operating TCP at a more buffer-optimal throughput (and give better performance overall). And though lacking bulk-transfer improving features, QUIC may gain improvements that help it outpace TCP for bulk transfers.
As for your bulk download, sorry, for the next few years, it seems we're just going to have to suffer (or chunk and download in parallel, if possible). But there are promising technologies on the horizon.
Exciting times lie ahead!
Edit: Fun example of bulk download issue on PS4. It's a TCP issue, it's an RTT issue and its solved by putting a proxy in the middle... oh, actually, not an RTT issue... it's Sony intentionally putting in a rate limit. (I guess in the case you don't have to curse CUBIC!)
- Okay, that was a lot, so here's a summary:
-
flow control,sliding windowalgorithms,slow startandcongestion controlare different concepts and play different roles in TCP flow controlprevents the sender from overloading the receiver with more data than it is prepared to receiveflow controlreceives direct information from the receiver on the state of the system (receive windowspace)flow controlrarely plays a role in TCP performance as network throughput is the bottleneck, not network buffer space.
-
- TCP
slow startonly bootstraps the TCP connection. Your bulk downloads are are governed primarily by TCP's
congestion controlalgorithm.Most TCP implementations use
hybrid slow startand putcongestion controlat the helm earlier in the connection than TCP of the 80s and 90s.
- TCP
- After repeated congestion collapses of the internet in the 1980s,
congestion controland theslow startalgorithm were added to TCP. congestion controlprevents the sender from overloading the network with more traffic than it can transmit.congestion controlreceives only indirect information such as packet loss, latency, network variability (unless usingECN). It must infer a safe value for thecongestion window(cwnd).congestion controlmust be designed to co-exist fairly with other network streams.
- After repeated congestion collapses of the internet in the 1980s,
-
CUBICis the most widely usedcongestion controlalgorithm and the default on Linux. CUBICexploits usable capacity by returning quickly (x^3) to last known capacity, generating a shark-fin pattern (unlikeRenowhich appears as a sawtooth).CUBICis not ACK-paced, but increasescwndbased on time.CUBICperforms reasonably well across RTTs.CUBICincludes modifications to increase convergence, such as centering the cubic at`0.9*W_maxwhen capacity appears to be decreasing.
-
- Tuning TCP on your system will not help bulk downloads, since the sender (server) is responsible for congestion control on the downstream.
You can't tune the server, but trust that engineers at Akamai, Amazon, CloudFlare, Google, are very concerned with performance.
-
QUICis a promising TCP+TLS+HTTP/SPDY replacement protocol. QUICincludes enhancements like rapid TLS handshakes, stream multiplexing without head-of-line-blocking, persistence across IP address changes, header compression, incremental packet numbers for retransmissions, and RTT based lost packet detection.Initial versions of
QUICappear unlikely to includeFEC, packet pacing, and advancedcongestion control(improvements that might benefit bulk transfers).QUICusesCUBIC, the samecongestion controlalgorithm as TCP!QUIC, for the time being, is unlikely to give improved performance for bulk transfers versus TCP. (So far, benchmarks confirm this).
-
-
BBRis a promising newcongestion controlalgorithm. Unlike
CUBICand most othercongestion controlalgorithms,BBRis latency-based and uses packet-pacing.BBRattempts to keep transmit rate at the level just before network buffers begin to queue packets.BBRperforms well with oversized buffers/buffer-bloat, unlike loss-basedcongestion control.Google claims significant performance increases using
BBR, but external testing shows issues in heterogeneous networks and co-existence withCUBIC.
-
Note: I have borrowed the "max probing" Cubic figure from Ha, Rhee, and Xu's original TCP CUBIC paper.
Footnotes
- 1
-
I should mention, this congestion thing isn't just collapse from multiple users. Jacobson tested scenarios where 2 machines would transmit 7% more packets than their gateway router had throughput-buffer for. By continuously transmitting at just 107% the gateway capacity, the transmission took 177% longer, spent 65% of its time on retransmits, and 7% of the packets had to be retransmitted 4 fricking times. Yes, even something simple and single-user like streaming music across your wifi requires
congestion controlto avoid subpar performance. - 2
-
Jacobson et al actually call their algorithm "soft start" after electrical engineering inrush current limiters of the same name. John Nagle, upon hearing the name, decided that "slow start" was a better term, and suggested this name on an IETF mailing list. I guess you listen to John Nagle. So in fairness, we have to blame Nagle and Jacobson for the name.
- 3
-
Technically, modern common TCP implementations have a slightly more complicated
slow start. In the interest of better link capacity detection, most implementations havemodified slow startwhereslow starthands the reins over tocongestion controlonce a certain treshold is reached. The ramp up to 122Mbps might take slightly longer under this scheme. - 4
-
This
Hybrid Slow Startimprovement is also by Ha and Rhee, theCUBICauthors: Hybrid Slow Start for High-Bandwidth and Long-Distance Networks. - 5
-
I assumed
CUBICavoided being ACK-paced to help its performance in high RTT networks. And perhaps that is an effect. SupposedlyCUBICis time based to avoid being too agressive on low RTT networks, a flaw thatCUBIC'spredecessorBICsuffered from. - 6
-
Google does not classify
BBRas a latency/delay based algorithm. Though it may be smarter than previous latency-based algorithmVegas,BBRstill seems pretty latency-based to me.